

Kısaca Cross Validation Aslında Nedir? Doğru Bilinen Yanlışlar

Çapraz Doğrulama ve Overfitting
Güzel bir başlangıç...
Makine öğrenmesi modelleri kurarken hepimiz o tatlı anı yaşamak isteriz: Modeli eğitiriz, test verisi üzerinde çalıştırırız ve iyi bir doğruluk elde ederiz. Göz alıcı bir sonuç alırız. Peki, buradaki asıl soru bu skora ne kadar güvenebiliriz? Ya sadece... şanslıysak?
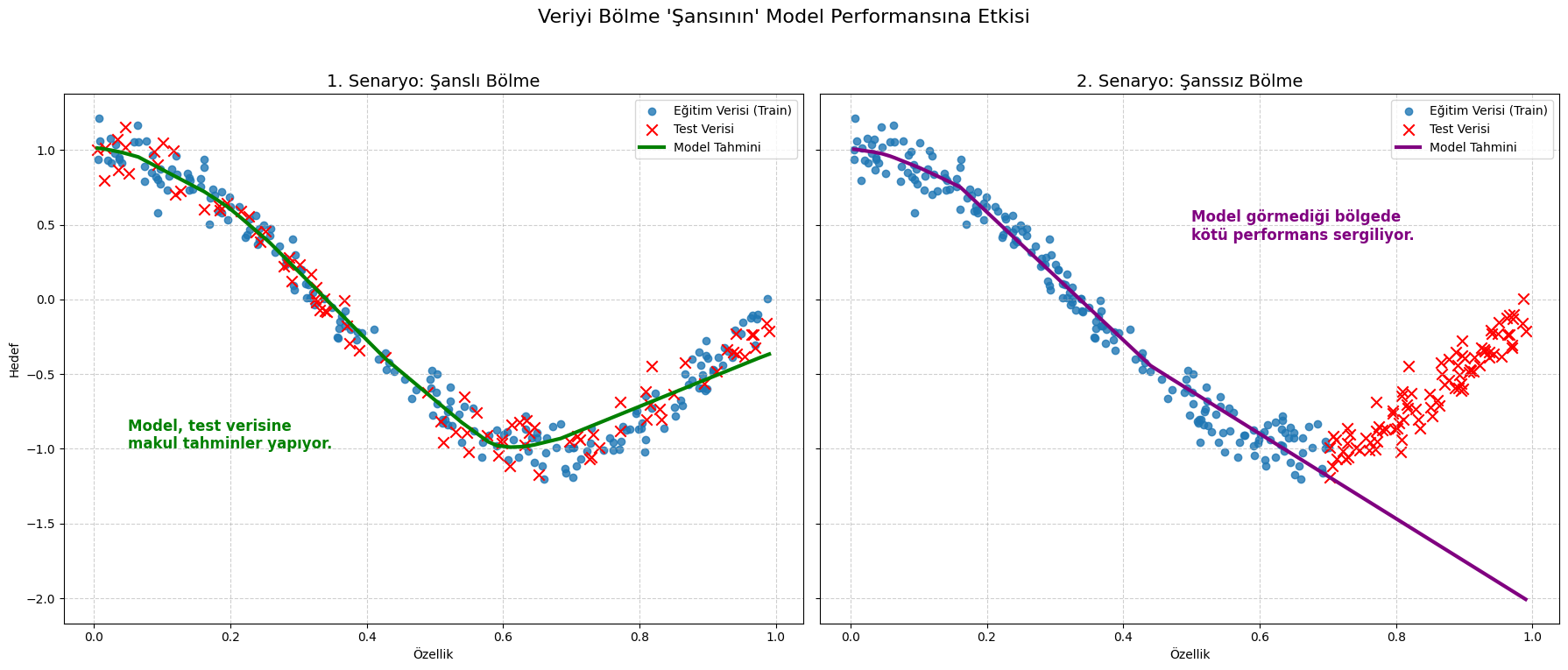
(Yukarıdaki grafik modele göre de değişiklik gösterecektir. Örneğin Polynomial Regression yukarıdan durumdan fazla etkilenmeyecektir.)
ML modellerini geliştirme aşamasında, tüm verisetimizi genelde train-test olarak ikiye ayırırız. Şunu da unutmamak gerekir ki, verilerin de yüksek boyutlu uzayda bir dağılımı vardır. Bu dağılımları bir karakteristik olarak düşünebilirsiniz. Siz bu bölme işlemini yaptığınızda, şansa bağlı olarak modelin iyi bileceği veya bilemeyeceği noktaları seçmiş olabilirsiniz. Bunun sonucunda modelin performansı olması gerekenden daha uzak bir değerde çıkar, bu da genel süreci yavaşlatabilir.
Kısaca Cross Validation Nedir?
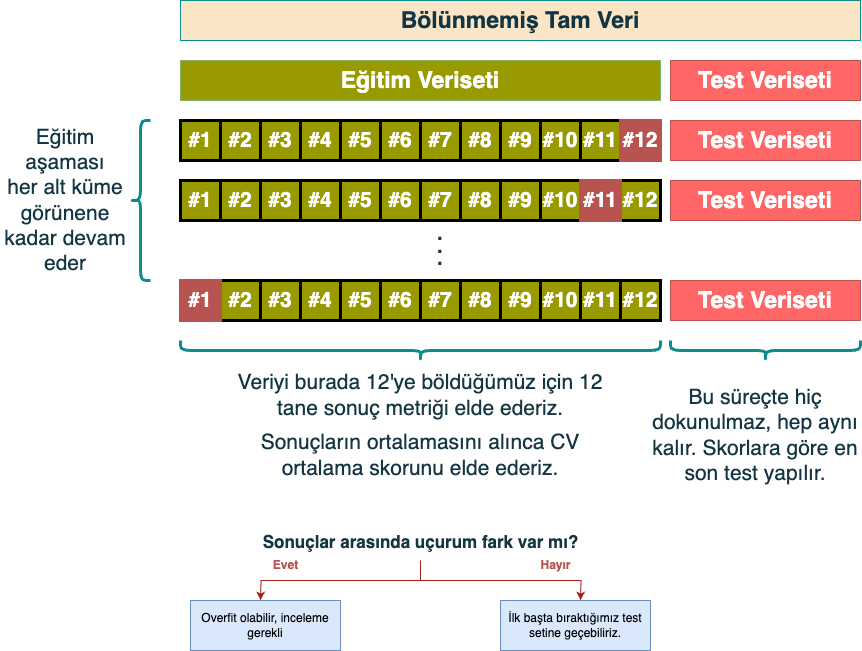
Yukarıda bahsettiğimiz ana problemden kaçınmak adına Cross Validation (Çapraz Doğrulama) yaparız. Bu yaklaşım, elimizde bulunan train verisetini belirli stratejiler (CV yapmanın birden fazla yolu vardır) kullanarak, alt küme (bunlara fold diyoruz) eğitim ve test setlerine böleriz. Böylece elimizde birden fazla alt eğitim kümesinde eğitilip performansı ölçülmüş modeller olur:
Doğru Bilinen Yanlışlar:
Cross Validation, overfitting'i (aşırı öğrenme) azaltır.
Cross validation, modelimizin performansının şansa bağlı çıkmadığını göstermek için kullanılan bir yaklaşımdır. CV yaparken model alt kümelere yine de overfit olabilir. Overfit olduğunda bazı ayarlamalar (model parametreleri - regularizasyon gibi) yaparak bunun üstesinden gelebiliriz, yani CV direkt olarak overfitting'i önler demek yanlış olur.
Ne kadar çok kat (fold), o kadar iyi sonuç.
Yukarıda verdiğimiz örnekte, train verisini 12 alt kümeye bölüp, her birinde modelin performansını ölçmüştük. Genelde verinin boyutuna bağlı olarak 5-7-10 gibi sayılar tercih edilebilir fakat burada bir trade-off vardır. Ne kadar fazla alt kümeye bölünürse, sonucun hesaplanması ve genel süreç o kadar uzayacaktır. Bunun sonucunda modelin performansını teoride daha iyi ölçebiliriz fakat bazen çıkan farklar da önemli olmayabilir. Özetle, sampling (örneklem) bias'ı azaltmış oluruz.
Cross Validation skoru modelin gerçek dünya performansıdır
CV kullandığımızda mevcut veri setinin özellik dağılımına dayalı bir tahmin sağlarız. Veri dağılımı değişimi (data drift), yeni veri türleri (yeniden eğitim gerektirebilir) gibi faktörler değişebileceğinden gerçek dünya performansı bu skordan sapabilir. Bu nedenle model canlıya alındıktan sonra izleme (monitoring) ve periyodik yeniden değerlendirme (re-validation) şarttır.
Kapanış
Umarım bu yazı yararlı olmuştur, bir sonraki yazılarda görüşmek üzere.
Kaan Bıçakcı
https://linktr.ee/kaanbicakci